Why Defense CV Teams Can Never Collect Enough Training Data
Defense and drone CV engineers face a persistent issue: field-collected data falls short for robust models, leaving gaps in edge cases like rare weather or occluded targets. No amount of flights or ground tests delivers the volume, diversity, or labels needed for mission-ready detection. Synthetic data addresses this directly by generating precise, scalable datasets that cut real-world collection needs by 50-90%.
Limits of Field Data Collection
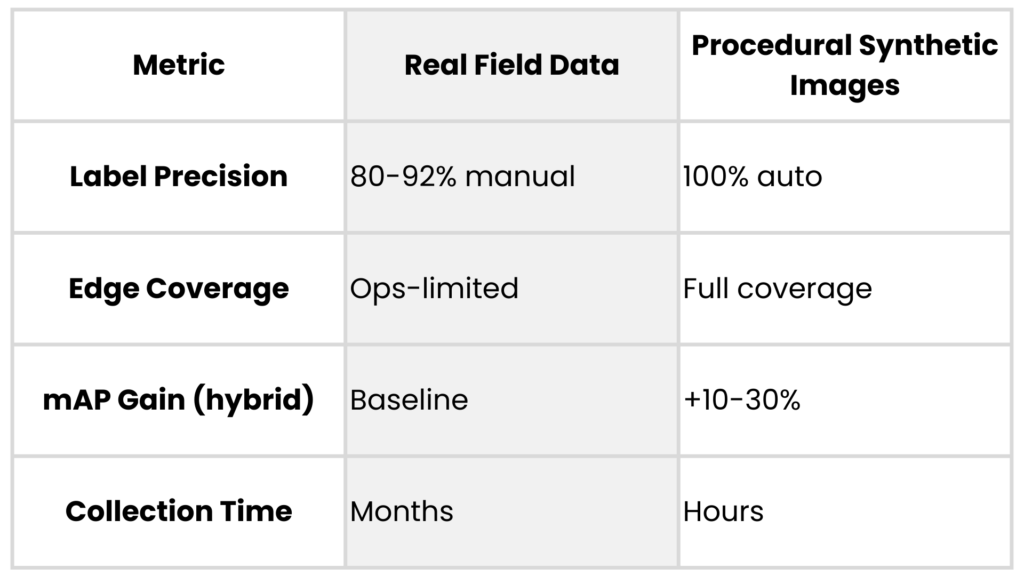
Field campaigns for drone payloads or ISR systems demand images across altitudes from 50m to 5km, lighting from dawn haze to IR night glow, and sensors like electro-optical (EO) vs. multispectral. Each sortie costs $200k+, yields only thousands of frames, and misses 80% of operational variations due to weather, regs, or classification locks.
Real data label accuracy hovers at 85-95% even with experts, prone to human error on small/distant objects. Teams burn months on campaigns that still leave models undertrained for novel scenes.

Security Constraints on Data Sharing
Classified data can’t tap open sources like COCO or crowdsource platforms. Export controls block partner exchanges; even internal siloed teams wait weeks for approvals. This fragments datasets, forcing siloed training on narrow domains and inflating domain gaps when deployed.
Adversarial risks compound it: leaked real imagery aids enemies, while synthetics stay clean and iterative without audits.
Synthetic Data: An Advantage for CV Teams
Procedural engines like those behind AI Verse’s Gaia and Helios parameterize scenes with physics-based rendering: vary object poses, textures, atmospheres via code, not diffusion models. This yields pixel-perfect labels (100% bounding boxes, segmentation masks) impossible manually, plus infinite diversity in occluded vehicles or drone swarms.
In tank detection tests, hybrid real-synthetic mixes boosted YOLOv8 mAP by 25% over real-only, converging 3x faster. Drone manufacturers use them for C-UAS: simulate rare low-light UAV intrusions, slashing false negatives by generating 1M frames overnight at a fraction of a price vs. $500k field equivalent.

Proven Use Cases in Defense CV
Synthetic images shine on object detection models: detecting partially foliage-hidden armor, detecting tanks from various angles, drone detection from thermal cameras are high altitude. Edge scenarios are easy to train for with accessible multispectral datasets with characteristics like dust, fog, lowlight, etc.

Aligning with 2026 Computer Vision Trends
In 2026, defense teams favor procedural synthetic data for its control and fit with new regulations like the EU AI Act, which favors synthetic datasets. Recent benchmarks confirm that synthetic imagery narrows the gap between simulated and real performance, a must-have for drone makers meeting tight C-UAS timelines.
Smart CV teams build feedback loops: train models, test on small real sets, then refine sim params for zero-shot generalization. Balancing classified real images with procedural synthetic ones results in deploying reliable models faster. This approach turns shortages into advantages for those ready to implement.

How to Build Better Computer Vision Models
Computer vision (CV) is revolutionizing industries such as smart home, security, and defense. From enabling fall detection to powering detection of weapons, CV applications are reshaping the way we interact with technology. However, achieving high-performing CV models remains a challenging task due to the dependency on high-quality, diverse datasets. Explore how synthetic images can address […]

Franco-German Partnership for Data Sovereignty in Defence AI.
We’re proud to announce a partnership between AI Verse and STARK. AI Verse, a French deep tech company and European leader in synthetic data generation for training artificial intelligence models, announces a strategic partnership with STARK, a German defence company that develops multi-domain unmanned systems. This collaboration aims to provide STARK with sovereign synthetic image datasets to train […]

Synthetic Data vs. Real-World Data: A Game Changer for AI Model Training
In the realm of AI and machine learning, the debate between synthetic datasets and real-world images is a pivotal one. Both have their merits, but when it comes to efficiency, flexibility, and performance, synthetic data is emerging as the clear frontrunner. Let’s explore why. Speed, Cost, and Flexibility: The Case for Synthetic Data Building a […]