

| AI Verse | Typical GenAI Tool | Generic Labeling Platform | |
|---|---|---|---|
| Generation speed | 4s/image | Variable | N/A (manual) |
| Label types per image | 8 auto | 0 | Task-specific |
| Indoor engine | HELIOS (dedicated) |  |  |
| Outdoor engine | GAIA (dedicated) | | |
| Physics-accurate (no hallucinations). |  | Risk | |
| Defense / C-UAS use cases | | | |
| Privacy (no real data required) | Fully synthetic | | |
Frequently Asked Questions: Synthetic Data for Computer Vision
Everything you need to know about generating and using synthetic training data.
What is synthetic data for computer vision?
Synthetic data for computer vision is artificially generated, fully-labeled image data used to train CV models — without capturing real-world footage. It is produced by procedural 3D rendering engines or generative models that simulate cameras, environments, objects, and lighting conditions. Every image comes with automatic ground-truth annotations including bounding boxes, segmentation masks, depth maps, and more. AI Verse generates photorealistic synthetic datasets at 4 seconds per image with 8 annotation types across any environment.
Why use synthetic data instead of real-world images for training CV models?
Real-world data collection is slow, expensive, and impossible in restricted environments like active military zones or rare failure scenarios. Synthetic data solves all three problems simultaneously: it can be generated on demand, at scale, with perfect labels, covering edge cases that may never occur naturally. For defense, security, and autonomous systems — where data access is legally or operationally constrained — synthetic training data is often the only viable path to a production-grade CV model.
Does synthetic data close the domain gap with real-world images?
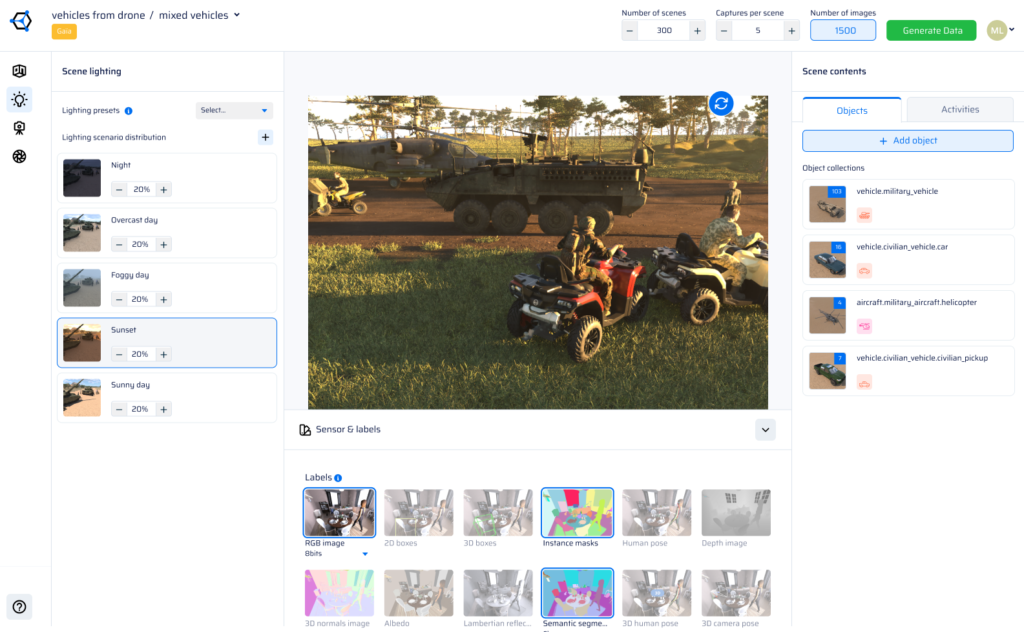
Yes — when generated with physics-based rendering and procedural scene diversity. The domain gap is the performance drop a model experiences when moving from training data to real-world inference. AI Verse closes this gap by simulating real sensor characteristics (lens distortion, noise, infrared response), generating diverse environmental conditions, and providing RGB + infrared data. Procedural generation, unlike GenAI image synthesis, ensures physically accurate geometry and lighting, which is critical for high-stakes CV applications.
What annotation types does AI Verse support?
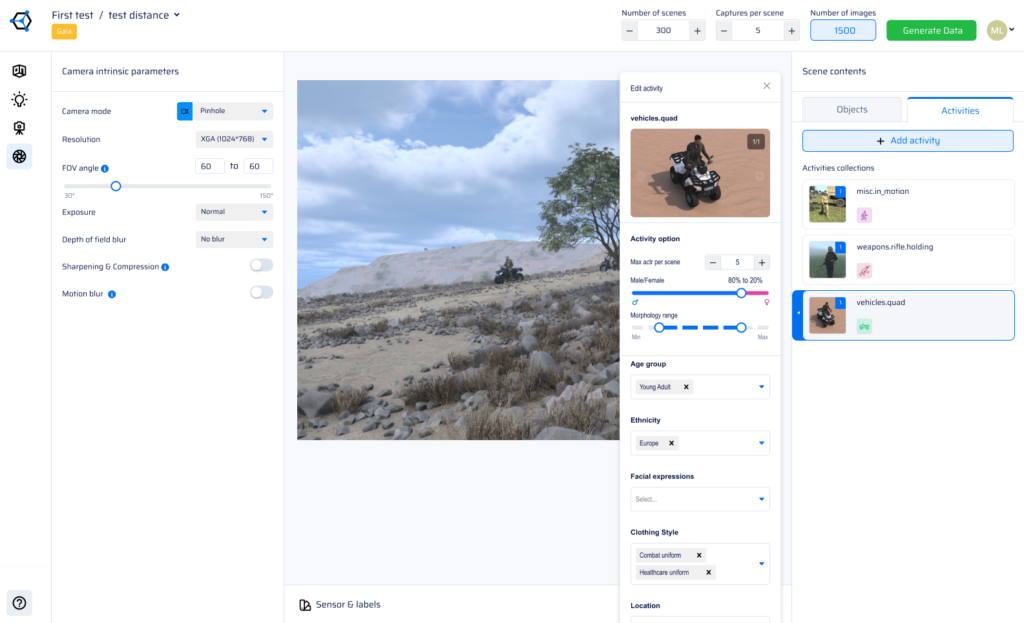
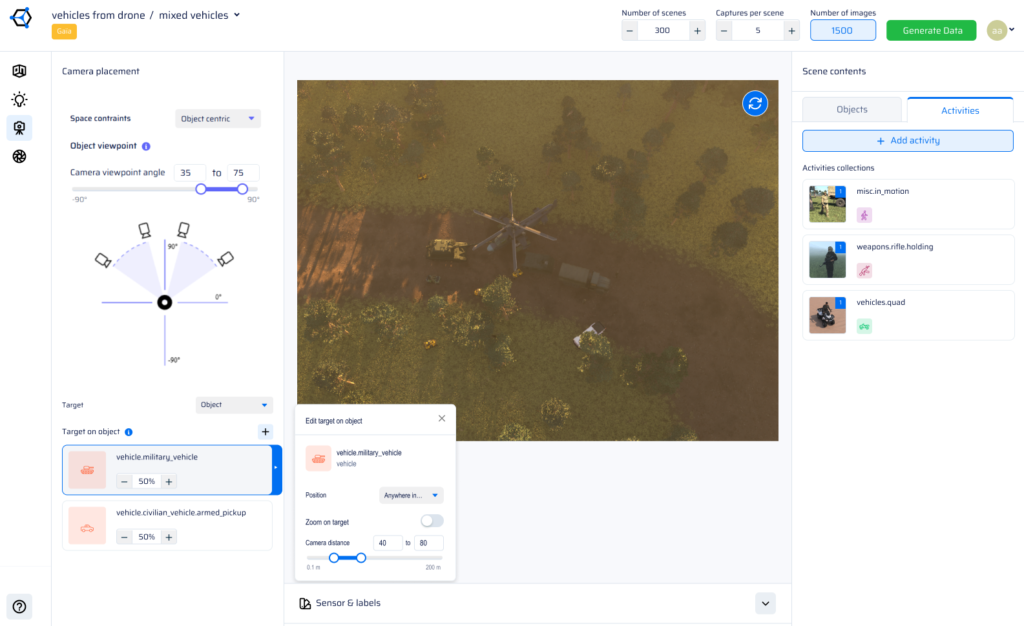
AI Verse supports 8 pixel-perfect annotation types generated automatically with every synthetic image: 2D bounding boxes, 3D bounding boxes, semantic segmentation, instance segmentation, depth maps, surface normals, optical flow, and skeleton / keypoint labels. All annotations are generated simultaneously at render time — no manual labeling, no outsourcing, no errors. This makes AI Verse synthetic datasets immediately usable for training object detection, segmentation, and pose estimation models.
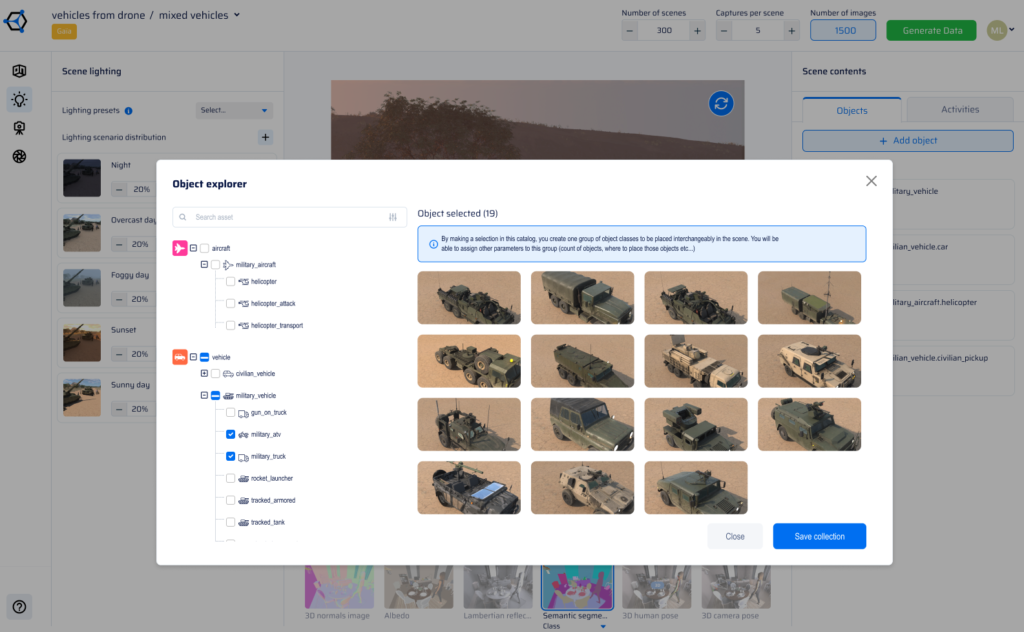
What computer vision use cases does synthetic data support?
Synthetic data for computer vision supports a wide range of mission-critical use cases: counter-UAS and drone detection, military vehicle and weapons recognition, perimeter security and intruder detection, autonomous navigation and obstacle avoidance, human posture and activity recognition, and smart surveillance. AI Verse's two procedural engines — GAIA for outdoor environments and ENVI for indoor and urban settings — cover the full spectrum of environments where CV models need to operate reliably.