Synthetic Images for Computer Vision Edge Cases
Computer vision engineers, researchers, and AI practitioners are building models for various use cases like autonomous systems, surveillance, and industrial inspection, aiming for near-perfect accuracy in real-world deployment. They cope with rare scenarios like occlusions, low light, or unusual angles that cause model failures despite strong benchmark performance. These edge cases demand data that’s often scarce, expensive, or privacy-risky to collect.
Fight Edge Cases in Computer Vision with Synthetic Images
What if your top-performing YOLO model crumbles when an object is behind a tree at dusk? Edge cases, those rare, unpredictable events, sink 30-50% of computer vision models in production, excelling in controlled tests, collapsing in real-world conditions.
Why Edge Cases Break Computer Vision Models
Real-world datasets do brilliant job on common scenarios but leave massive gaps in scenarios like foggy vehicle detection or occluded objects from odd angles. Collecting this data means costly dispatch of objects and actors to the field, additionally waiting for desired weather and lighting conditions. Next follows a lengthy manual labeling (prone to errors), and privacy headaches under regs like GDPR, especially in defense or surveillance. This long process can result in models overfitting to biases, spiking false positives/negatives at the decisive moment.
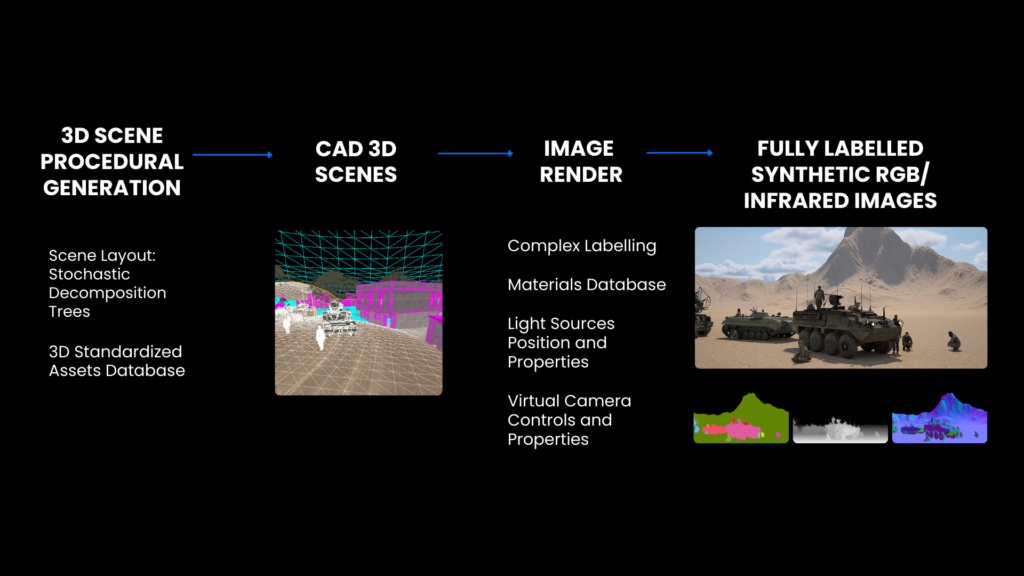
Procedural Synthetic Images: The Solution
Procedural synthetic data generation offers a way to address real-life imagery gaps. Engines can generate large volumes of images with precise control over scene parameters, such as lighting, weather, occlusions, camera angles, sensor characteristics, etc. Additionally, images come with pixel-perfect labels such as 2D and 3D bounding boxes, segmentation masks, or depth maps. Unlike images generated with GenAI that may cause domain gaps, procedural image generation allows you to design specific failure modes and test how well a model generalizes under controlled conditions.

This is not just theoretical. For example, a drone interceptor producer retrained their model with 15,000 synthetic thermal images of drones viewed from the ground up to 125m altitude, which led to ~23% improvement in model’s detection precision. Synthetic thermal image datasets closed domain gaps faster and increased detection recall, enabling more efficient iteration cycles and faster deployment.
Proven Workflow for CV Engineers
For computer vision engineers this means a more methodological workflow:
- Identify failure modes through error analysis on real data.
- Generate thousands of images that fit your need overnight using procedural tools like AI Verse Procedural Engine.
- Retrain and validate, then repeat.
In practice, this can significantly reduce annotation effort and data‑collection costs by 80% while improving robustness to motion blur, sensor noise, and other artifacts. Models generalize better, handling “unseen” like motion blur or sensor noise without endless relabeling Because the data is synthetic, it can also be generated without privacy concerns, which is particularly valuable in sensitive domains.
Synthetic Data Trends in Computer Vision
Industry trends point toward broader adoption of synthetic data in computer vision, with forecasts suggesting that a growing share of training data will be synthetic by the late 2020s. As models become more complex and regulations around data privacy tighten, procedural and generative synthetic‑data tools are likely to become standard components of the development pipeline, especially for safety‑critical applications such as autonomy and industrial inspection.
If you’re working on edge‑case robustness in your own projects, it’s worth experimenting with synthetic data to see how it changes your model’s behavior. What edge cases are most challenging for your current pipeline? I’d be interested to hear how others are approaching this.
The Future Synthetic Landscape
By 2028, Gartner predicts 70% of CV models will lean on synthetic data for multimodal robustness, driven by regs and complexity. Procedural engines like Gaia and Helios will became a standard components of the AI, guaranteeing safer model training and it is likely that the real data will act as the supplement, not star.
Frequently Asked Questions: Synthetic Data for Computer Vision
Everything you need to know about generating and using synthetic training data.
What is synthetic data for computer vision?
Synthetic data for computer vision is artificially generated, fully-labeled image data used to train CV models — without capturing real-world footage. It is produced by procedural 3D rendering engines or generative models that simulate cameras, environments, objects, and lighting conditions. Every image comes with automatic ground-truth annotations including bounding boxes, segmentation masks, depth maps, and more. AI Verse generates photorealistic synthetic datasets at 4 seconds per image with 8 annotation types across any environment.
Why use synthetic data instead of real-world images for training CV models?
Real-world data collection is slow, expensive, and impossible in restricted environments like active military zones or rare failure scenarios. Synthetic data solves all three problems simultaneously: it can be generated on demand, at scale, with perfect labels, covering edge cases that may never occur naturally. For defense, security, and autonomous systems — where data access is legally or operationally constrained — synthetic training data is often the only viable path to a production-grade CV model.
Does synthetic data close the domain gap with real-world images?
Yes — when generated with physics-based rendering and procedural scene diversity. The domain gap is the performance drop a model experiences when moving from training data to real-world inference. AI Verse closes this gap by simulating real sensor characteristics (lens distortion, noise, infrared response), generating diverse environmental conditions, and providing RGB + infrared data. Procedural generation, unlike GenAI image synthesis, ensures physically accurate geometry and lighting, which is critical for high-stakes CV applications.
What annotation types does AI Verse support?
AI Verse supports 8 pixel-perfect annotation types generated automatically with every synthetic image: 2D bounding boxes, 3D bounding boxes, semantic segmentation, instance segmentation, depth maps, surface normals, optical flow, and skeleton / keypoint labels. All annotations are generated simultaneously at render time — no manual labeling, no outsourcing, no errors. This makes AI Verse synthetic datasets immediately usable for training object detection, segmentation, and pose estimation models.
What computer vision use cases does synthetic data support?
Synthetic data for computer vision supports a wide range of mission-critical use cases: counter-UAS and drone detection, military vehicle and weapons recognition, perimeter security and intruder detection, autonomous navigation and obstacle avoidance, human posture and activity recognition, and smart surveillance. AI Verse's two procedural engines — GAIA for outdoor environments and ENVI for indoor and urban settings — cover the full spectrum of environments where CV models need to operate reliably.

Real-Life Data vs. Synthetic Data: How Computer Vision Engineers Allocate Their Time
Computer vision engineers are at the forefront of teaching machines to “see” and understand the world. Their daily practices, and ultimately the pace of AI innovation, are shaped by the kind of data they use—either real-life imagery painstakingly collected from the physical world, or synthetic data generated by advanced simulation engines. Let’s examine how these […]

How Automated Annotation with Synthetic Data Elevates Model Training in Computer Vision
In contemporary computer vision development, the shortage of accurately labeled data remains one of the most persistent bottlenecks. Manual annotation is costly, slow, and prone to inconsistency, consuming over 90% of many project resources. Synthetic image generation combined with automated annotation offers a powerful solution by producing massive volumes of precisely labeled images. This accelerates […]

Discover how synthetic data revolutionized our tank detection model training.
Training a tank detection model using conventional data presents several challenges. One of the biggest obstacles is the scarcity of labeled data. Tanks are not everyday objects, and acquiring enough annotated images for training is extremely difficult due to confidentiality of images.