Real-Life Data vs. Synthetic Data: How Computer Vision Engineers Allocate Their Time
Computer vision engineers are at the forefront of teaching machines to “see” and understand the world. Their daily practices, and ultimately the pace of AI innovation, are shaped by the kind of data they use—either real-life imagery painstakingly collected from the physical world, or synthetic data generated by advanced simulation engines.
Let’s examine how these differences define the daily workflow in computer vision, highlighting the distinct advantages and opportunities offered by each.
The Real-Life Data Engineer
Key Responsibilities:
- Acquiring real-world images and videos
- Cleaning and annotating data, often by hand or via crowd-sourcing
- Designing and developing computer vision models
- Validating models against real scenarios and edge cases
- Addressing data quality, privacy, and edge case challenges
Typical Time Allocation:
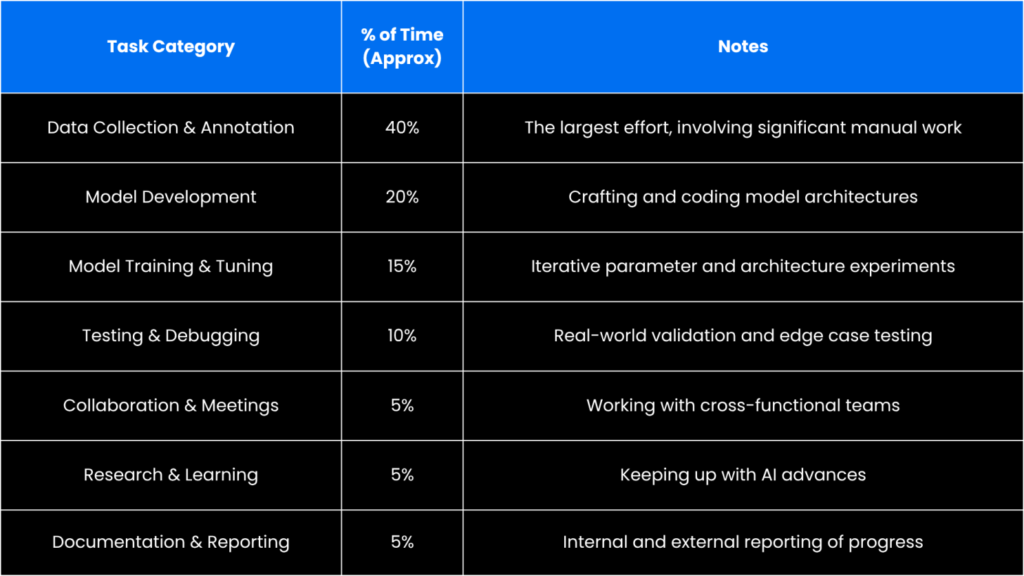
Why So Much Time On Data?
Real-world data, while richly detailed, comes with inherent complexity. Each image must be collected, cleaned, and meticulously annotated. Privacy, data diversity, and edge-case identification further increase the effort needed to achieve robust computer vision results.
The Synthetic Data Engineer
Key Responsibilities:
- Generating large, diverse synthetic datasets using advanced procedural and simulation engines such as AI Verse’s Gaia
- Validating and curating synthetic datasets for relevance and completeness
- Training AI models on pixel-perfect, automatically labeled synthetic images
- Applying domain adaptation techniques to ensure strong real-world performance
- Iteratively refining both datasets and models for optimal coverage and quality
Typical Time Allocation:
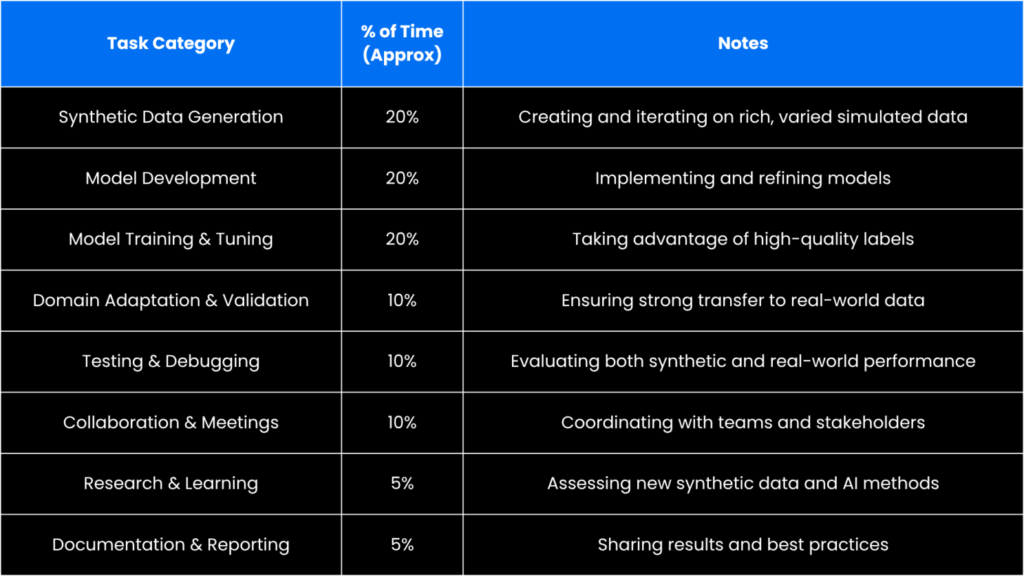
What Sets Synthetic Data Apart?
Engineers using synthetic data are empowered by high-fidelity simulation tools that allow them to automatically generate and label image data at massive scale. This eliminates the need for manual annotation, freeing up time for developing, tuning, and validating advanced models. The result is a more efficient AI training that accelerates innovation and enables comprehensive coverage, including rare and safety-critical scenarios difficult to capture in the real world.
Side-by-Side Comparison
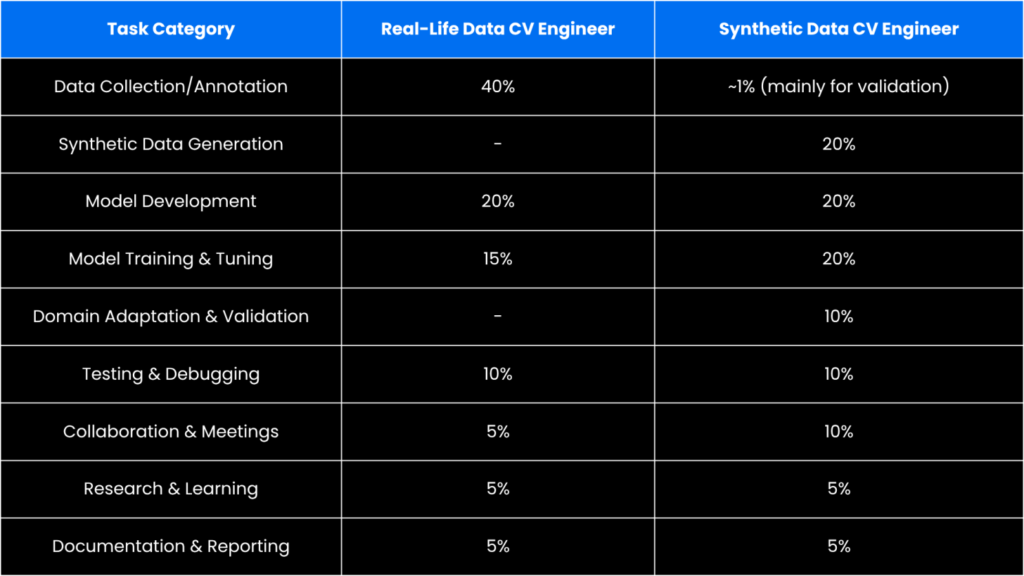
Why More Teams Choose Synthetic Data
Synthetic data offers a transformative approach to computer vision:
- Efficient, scalable, and diverse dataset generation—enabling rapid iteration and innovation.
- Comprehensive coverage of rare and challenging scenarios, ensuring robust model performance across use cases.
- Bypassing privacy constraints—synthetic assets are customizable and inherently anonymous.
- Automated, pixel-perfect labeling eliminates manual annotation, maximizing engineering productivity.
- Flexible domain adaptation and validation processes that ensure high performance when deployed in the real world.
Both real-world and synthetic data demand high-level collaboration, technical excellence, and continuous learning. However, synthetic data empowers engineers to focus more on driving model accuracy, expanding use case coverage, and accelerating the path from idea to deployment.
As AI advances and applications expand, synthetic images are proving crucial for boosting model accuracy, coverage, and development speed. For companies building computer vision solutions, the synthetic-first approach opens new possibilities—delivering the data needed to fuel the future of intelligent machines.
Data source: AI Verse survey of computer vision engineers (2025). Time allocation figures represent median responses across teams using traditional real-world data collection pipelines versus synthetic data generation workflows.

Five Trends in Computer Vision for 2025
As we approach 2025, the computer vision landscape is being reshaped by advances in AI, hardware, and interdisciplinary integration unlocking new possibilities for optimizing model performance and addressing challenges once considered impossible. Here are five key trends to watch: 1. Edge AI The demand for real-time decision-making is driving the optimization of computer vision models […]

A Practical Guide to Labels Behind Computer Vision Models
Data labels in computer vision are annotations that identify what a model is looking at — marking object boundaries, classifying pixel regions, or flagging keypoints. Without precise labels, a model cannot learn to distinguish between classes or accurately localize objects. Label quality is the most direct determinant of model performance. What are data labels in […]

How Synthetic Images Power Edge Case Accuracy in Computer Vision
Edge cases in computer vision are rare, atypical, or safety-critical scenarios that AI models fail to detect reliably because they appear too infrequently in real-world datasets — a camouflaged vehicle in fog, a pedestrian emerging at night, or a partially occluded object. Synthetic image generation makes it possible to produce and annotate these rare scenarios […]